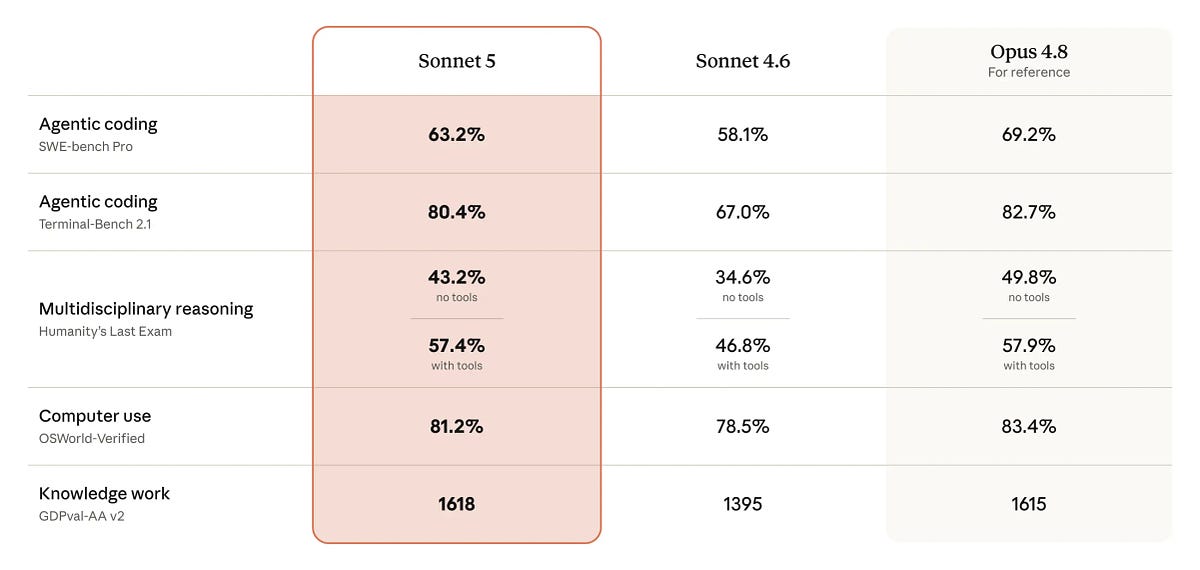
If you’re a developer who watched Opus 4.8 pull ahead on agentic tasks over the last few months, Sonnet 5 is the model that brings those capabilities back to a price that makes sense for daily API calls. Announced yesterday by Anthropic, Claude Sonnet 5 closes the gap with Opus 4.8 across the dimensions that matter most for shipping real software: reasoning, tool use, coding, and autonomous multi-step execution — at roughly half the cost.
What Makes Sonnet 5 Different
Sonnet 5 is the most agentic Sonnet model Anthropic has released. It can make plans, use browsers and terminals, and run autonomously at a level that previously required Opus-class models. On BrowseComp, a benchmark for agentic search, Sonnet 5 at high effort levels matches Opus 4.8 performance while staying on a much lower cost curve. On OSWorld-Verified, a computer-use evaluation, the story is similar.
The improvement over Sonnet 4.6 is substantial across the board. Anthropic published benchmarks show gains in reasoning, tool use, coding, and knowledge work — the four pillars of agentic development. For developers, this means the model you reach for by default in Free and Pro plans can now handle tasks that used to be Opus-only.
Pricing That Actually Moves the Needle
The pricing story is where Sonnet 5 gets interesting for anyone paying API bills. Through August 31, 2026, introductory pricing sits at $2 per million input tokens and $10 per million output tokens. After that, standard pricing kicks in at $3 and $15 respectively. Compare that to Opus 4.8 at $5 and $25, and the math becomes straightforward.
There is one tradeoff. Sonnet 5 uses an updated tokenizer that maps the same input to roughly 1.0 to 1.35 times more tokens depending on content type, similar to the change Anthropic introduced with Opus 4.7. Anthropic set the introductory pricing to be roughly cost-neutral during the transition, but teams running high-volume pipelines should benchmark their actual token counts before assuming the per-token savings translate directly.
The effort parameter is worth understanding. Sonnet 5 can operate at different effort levels — low, medium, high, and extra high — letting you pay for capability only when you need it. A quick lint check runs at low effort; a full codebase refactor runs at high. The cost-performance curves published by Anthropic show that medium effort on Sonnet 5 already beats Sonnet 4.6 at any effort level, and high effort comes close to Opus 4.8 on many tasks.
What Early Access Partners Found
The early access feedback tells a consistent story: Sonnet 5 finishes tasks where prior Sonnet models stopped short. Zimu Li at Canva described it handling multi-step software engineering work across messy technical contexts. The Rust engineer Neel Chotai reported that Sonnet 5, unprompted, wrote a reproducing test, implemented the fix, then stashed it to confirm the bug came back without the change — all in a single pass.
Dominic Elm, a founding engineer, noted that Sonnet 5 shines on brownfield code — race conditions, hidden tests, the parts nobody wants to touch. For Lovable co-founder Fabian Hedin, the model ability to refuse unsafe requests was just as important as its ability to build. At ClickHouse, Ryadh Dahimene reported that Sonnet 5 reasons in tighter steps and gets users to answers faster.
Safety That Scales with Agency
Giving a model more autonomy raises the stakes on safety. Anthropic pre-deployment evaluations found that Sonnet 5 is better than Sonnet 4.6 at refusing malicious requests, resisting prompt injection hijack attempts, and avoiding hallucination and sycophancy. Its overall rate of misaligned behavior on automated auditing is lower than its predecessor.
On cybersecurity, Anthropic chose restraint. Sonnet 5 was never able to develop a working exploit for Firefox vulnerabilities in testing — something Opus 4.8 and Mythos 5 both managed. Cyber safeguards are enabled by default, and the model is part of the Cyber Verification Program for organizations that need reduced guardrails.
How to Try Sonnet 5 Today
Sonnet 5 is the default model for Free and Pro plans starting today. It is also available to Max, Team, and Enterprise users. For developers, it is accessible through Claude Code and the Claude Platform API using the model ID claude-sonnet-5. Anthropic has raised rate limits across Chat, Cowork, Claude Code, and the Platform to accommodate the higher token usage of higher effort levels.
FAQ
How does Claude Sonnet 5 compare to Opus 4.8 for coding tasks?
Sonnet 5 at high and extra-high effort levels comes close to Opus 4.8 on coding benchmarks and real-world pull requests. Early access partners reported it carrying complex multi-file changes through to tested, verified results. For most daily development work, Sonnet 5 is sufficient — reach for Opus 4.8 only for the hardest problems where you need maximum capability regardless of cost.
What is the effort parameter and how does it affect cost?
The effort parameter lets you choose how much inference compute the model spends on a task. Low effort is cheapest and fastest, suitable for simple lookups or linting. High and extra-high effort spend more tokens to produce better results on complex tasks like code review or architectural analysis. You pay per token, so higher effort costs more — but only when you need it.
Is Sonnet 5 available in Claude Code and the API?
Yes. Sonnet 5 is available in Claude Code and through the Claude Platform API. The model ID is claude-sonnet-5. Rate limits have been increased across all tiers to support the higher token usage from effort-level selection.
Does the new tokenizer make Sonnet 5 more expensive in practice?
The updated tokenizer maps the same input to 1.0 to 1.35 times more tokens depending on content type. Through August 31, introductory pricing is set to be roughly cost-neutral versus Sonnet 4.6. After that, the standard $3/$15 pricing still represents a meaningful improvement in capability per dollar, especially at medium effort levels.
How safe is Sonnet 5 for autonomous agent workflows?
Sonnet 5 performs better than Sonnet 4.6 on every safety metric Anthropic measures: lower hallucination, lower sycophancy, better refusal of malicious requests, and better resistance to prompt injection. Cyber safeguards are enabled by default. If you are building agents that operate on user behalf, Sonnet 5 is the safest Sonnet yet for that use case.
Try Sonnet 5 Today and Decide for Yourself
If you are on a Free or Pro plan, Sonnet 5 is already the default — open Claude and see the difference. If you are building on the API, spin up claude-sonnet-5 at the introductory pricing and run it against your test suite. The model costs less than Opus, handles more than any Sonnet before it, and the only way to know if it works for your specific workload is to try it. Set aside 30 minutes this week to run your most painful agentic task through Sonnet 5 and compare the result.
No comments :
Post a Comment