If you’re building a voice agent in 2026, you’ve probably noticed that picking a speech-to-speech model is still mostly vibes. The demos all sound great and the only way to know which one is best for your product is to wire up four APIs and run your own eval. On June 23, 2026, Artificial Analysis tried to make that easier: they published the Speech-to-Speech Index, a single composite score for native S2S model quality.
What the index actually measures
The index isn’t one benchmark — it’s an equally weighted average of three. Each tests a different capability a voice agent needs in production.
Big Bench Audio is the reasoning layer: 1,000 questions across formal fallacies, navigation, object counting, and web of lies. The model has to think before it speaks.
Full Duplex Bench is the conversation layer. It scores pauses, turn-taking, interruptions, and backchannels — the parts of a real phone call that demos never show.
τ-Voice is the agentic layer. It runs end-to-end customer-service scenarios across airline, retail, and telecom and checks whether the model completes the task.
A model has to have valid scores on all three to be ranked at all. That’s a meaningful bar: the index is opinionated about what good looks like for a real product.
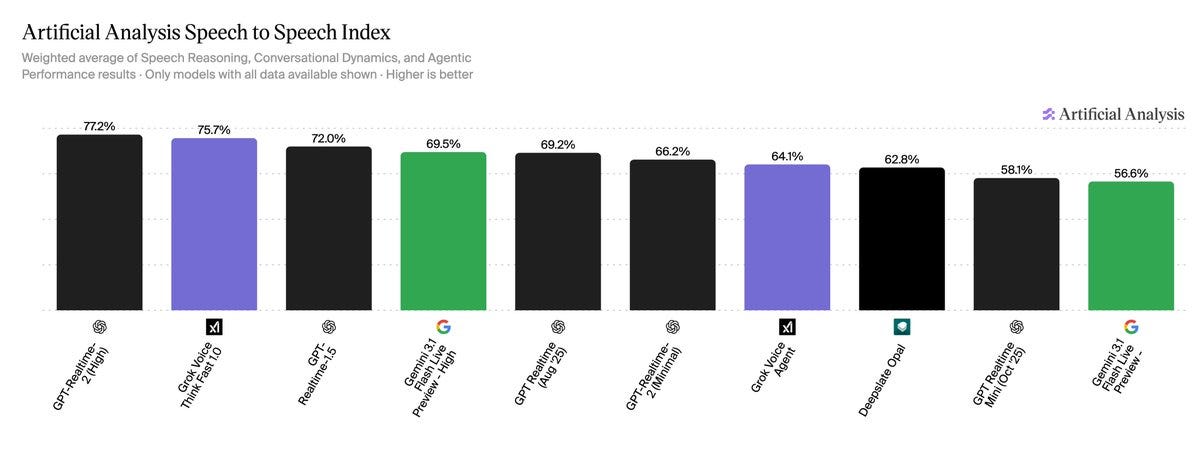
The quality leaderboard
The composite scores for the four models in the index:
- OpenAI GPT-Realtime-2 (High) — 77.2%
- 2. xAI Grok Voice Think Fast 1.0–75.7%
- 3. OpenAI GPT-Realtime-1.5–72.0%
- 4. Google Gemini 3.1 Flash Live Preview (High) — 69.5%
The top four are within 8 points of each other, so there isn’t a runaway winner. But the shape of each model’s wins is different. GPT-Realtime-2 leads on Conversational Dynamics: it handles the awkward, real-time parts of conversation better than the rest. Grok Voice Think Fast 1.0 leads on Agentic Performance: it actually finishes customer-service tasks.
For builders, that split is the most useful signal in the index. Phone agents should weight Grok’s lead higher; long-form assistants should weight OpenAI’s lead higher.
Speed: time to first audio
For voice products, the metric that actually drives perceived quality is Time to First Audio (TTFA) — how long from the user finishing a sentence to the model starting its response:
Deepslate Opal — 0.44s
GPT-Realtime-1.5–0.82s
Grok Voice Think Fast 1.0–1.25s
GPT-Realtime-2 (High) — 2.33s
Gemini 3.1 Flash Live Preview (High) — 2.98s
The pattern: the higher the model scores on quality, the slower it tends to be. GPT-Realtime-2 is the best model in the test and 5x slower than Deepslate Opal. For a fast-back-and-forth IVR, 2.3 seconds of dead air feels broken. For a thoughtful assistant, that latency may be worth it.
Deepslate Opal isn’t in the quality ranking (it doesn’t yet have valid scores on all three sub-benchmarks), but its 0.44s TTFA opens up new product categories if the quality story holds up under your own testing.
Cost: what you’ll pay per interaction
The index also reports per-interaction cost:
Gemini 3.1 Flash Live Preview (Minimal) — $1.50
Gemini 3.1 Flash Live Preview (High) — $1.75
Grok Voice Think Fast 1.0 — $3.00
GPT-Realtime-2 (High) — $4.14
Deepslate Opal’s cost isn’t reported in the index.
The cheapest model is 2.7x cheaper than GPT-Realtime-2, and Gemini’s pricing is genuinely aggressive for a frontier-tier model. For any product where unit economics matter — a customer-service line, a high-volume voice assistant — the math on Gemini Flash Live is hard to beat. The trade-off is real, though: the cheapest model is also the lowest-scoring on the quality leaderboard.
What this means for builders
The index is a starting point, not a verdict. It tells you how four frontier S2S models compare on a fixed set of tasks. It doesn’t tell you how they’ll perform on your audio, your users, your domain, or your edge cases.
The useful pattern is this: use the index to pick a shortlist of one or two models, then run a small evaluation on your own data. A 50-call eval on your own audio with your own success metric is worth more than any external benchmark.
The split between GPT-Realtime-2’s Conversational Dynamics lead and Grok’s Agentic Performance lead is the most useful signal for product builders. Most voice products in 2026 are either more like a phone call (where dynamics matter) or more like a task (where agentic performance matters). Pick accordingly.
FAQ
What’s the difference between native speech-to-speech and a stitched pipeline?
A native S2S model takes audio in and produces audio out directly, without a separate speech-to-text → LLM → text-to-speech pipeline. Stitched pipelines are slower, lose prosody and emotion through the text step, and cost more to run. All four models in this index are native S2S.
What does Conversational Dynamics measure, and why does it matter?
Conversational Dynamics comes from the Full Duplex Bench subset — it scores pauses, interruptions, backchannels (“uh-huh”), and turn-taking. Models that score well here feel like they are actually listening. Models that score poorly feel like they are waiting for their turn to talk.
Why is the cheapest model not the quality leader?
Quality and cost are correlated in every model category, and voice is no exception. Gemini 3.1 Flash Live Preview is the cheapest ($1.50) and the lowest in the quality ranking (69.5% vs. 77.2% for GPT-Realtime-2). Every percentage point of quality costs more in compute.
Is OpenAI’s GPT-Realtime-2 worth the 2.7x cost over Gemini Flash Live?
It depends on what you’re building. For a 10-minute customer-service call where the user is venting and interrupting, the Conversational Dynamics lead is probably worth the cost. For a 30-second IVR tree, it’s overkill and the 2.33s TTFA is going to hurt.
Should I pick a model based on this index or test on my own data?
Test on your own data. The index is a shortlist tool, not a decision tool. Real production audio has noise, accents, domain jargon, and edge cases that benchmarks don’t capture. Run at least 50 calls against the top two candidates before you commit.
The index gives builders a useful starting point: four frontier models, one composite score, and clear data on what’s slow, cheap, and good at the parts of conversation that matter. Treat it as a shortlist, run a 50-call eval on your own audio, and let your users’ actual call quality be the final tiebreaker.
No comments :
Post a Comment