GitHub benchmarked its agentic harness across 5 test suites and found that model-agnostic agents deliver the same results for fewer tokens. Here’s what that means for your next project.
If you’re a developer deciding between Copilot, Claude Code, and Codex CLI, you’ve probably seen plenty of claims but not much controlled data. Last week, GitHub published a head-to-head comparison of the Copilot agentic harness against the native harnesses that ship with leading models — holding the model and task fixed across five separate benchmarks.
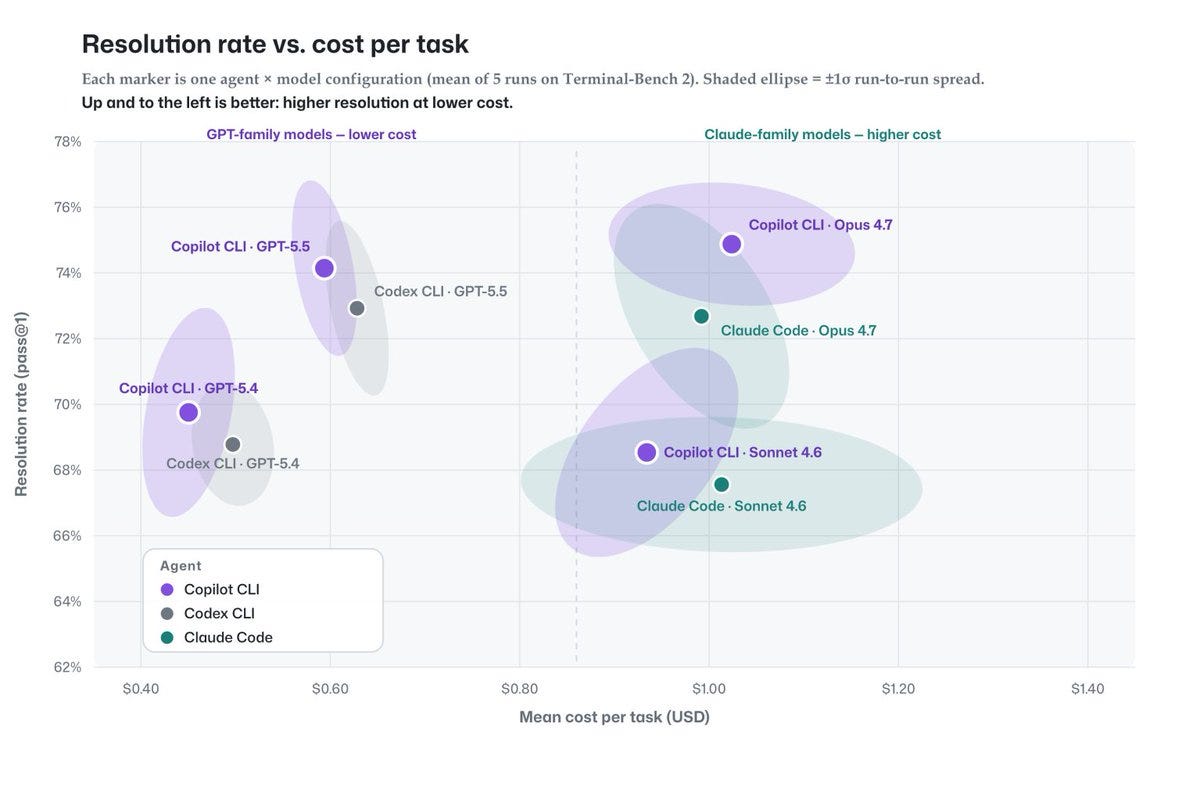
The results land on a scatter plot that’s hard to ignore. Copilot CLI clusters in the top-left corner: high task resolution at low cost. Claude Code and Codex CLI sit to the right, spending more per task for equivalent or worse resolution.
What GitHub Actually Tested
GitHub ran every harness-model combination across five benchmark suites: SWE-bench Verified, SWE-bench Pro, SkillsBench, TerminalBench, and Win-Hill. The methodology held the model constant and varied only the harness, isolating the harness as the variable rather than the model’s capability. On TerminalBench 2 alone, every configuration was run five times with a shaded ±1σ ellipse to capture variance.
This matters because most AI coding tool comparisons conflate model quality with harness quality. A great model inside a wasteful harness gives you expensive, slow results. A decent model inside an efficient harness might outperform it.
The Chart That Changes the Calculation
The scatter plot splits into two clear clusters. On the left, GPT-family models (GPT-5.4, GPT-5.5) run at $0.40–$0.60 per task with 65–70% resolution. On the right, Claude-family models (Sonnet 4.6, Opus 4.7) run at $0.80–$1.40 per task with 68–78% resolution. Copilot CLI holds the top-left position across both clusters — above-average resolution with below-average cost.
Why Token Efficiency Is the Real Story
The headline number isn’t resolution — it’s tokens. Across most configurations, the Copilot agentic harness used fewer tokens to reach the same result. Fewer tokens means faster feedback loops, lower latency during interactive use, and cheaper CI/CD integrations.
For a team running AI-assisted code reviews or automated patch generation, token count maps directly to cost per operation. A harness that wastes tokens on verbose planning traces adds up fast. At scale, the difference between $0.60 and $1.20 per task isn’t academic — it’s your monthly infrastructure bill.
Vendor-native harnesses are the worst offender. They’re optimized for one model’s output format and don’t adapt. The Copilot harness, by contrast, is model-agnostic — it speaks the same protocol to any underlying model and strips out overhead.
The 20-Model Advantage No One’s Talking About
Consider a concrete scenario. You’re iterating on a React component. Quick feedback matters, so you route the task to GPT-5.5 through Copilot — fast, cheap, good enough. Then you hit a tricky race condition in the state management. You route the same conversation to Claude Opus 4.7 — deeper reasoning, more tokens, higher cost, but the bug is complex. Once the fix is validated, you’re back to the fast model.
This is impossible with vendor-native harnesses. Codex CLI locks you into OpenAI’s model line. Claude Code’s harness locks you into Anthropic’s. The Copilot agentic harness supports more than 20 models and lets you switch per task without changing your workflow.
How to Choose Your AI Coding Agent Now
Prioritize model diversity. A team using a single model’s native harness is one API deprecation away from rebuilding their workflow. A model-agnostic harness insulates you.
Watch cost per task, not cost per token. A tool that uses 2x the tokens for the same result is expensive regardless of per-token pricing. The benchmark data gives you the real metric.
Test on your own workload. Run a side-by-side on your most common task — a PR review, a refactor — and measure both resolution and tokens.
The data doesn’t say Copilot is categorically better. It says a well-designed agentic harness beats a vendor-locked one, regardless of the model underneath.
FAQ
Does Copilot support models other than OpenAI?
Yes. The Copilot agentic harness works with more than 20 models from OpenAI, Anthropic, and others. You can switch between them per task without changing your editor or workflow.
How do the benchmarks translate to real-world use?
Benchmarks measure task-completion accuracy in controlled environments. Real-world results vary by codebase, but the relative efficiency advantage — fewer tokens for the same resolution — tends to carry over because it’s a harness property, not a model property.
Should I switch from Claude Code to Copilot based on this data?
Not necessarily. If Claude Code gives you results you’re happy with and cost isn’t a concern, there’s no urgent reason to switch. But if you’re comparing tools from scratch or feeling the cost of verbose agent traces, the data suggests a model-agnostic harness delivers better economics.
What is an agentic harness?
It’s the middleware between you and the model. It decides how to break a task into steps, what context to include, when to call tools, and how to format the response. A good harness minimizes wasted tokens while maximizing task completion.
Can I use Copilot’s harness with my own API keys?
Copilot is a paid GitHub subscription. You can’t bring your own model API keys, but the model choice within the harness — across 20+ models — is included in the subscription.
Pick a Task and Measure
Open GitHub’s chart and look at the scatter plot for yourself. Then pick one task from your daily work — something you’d normally ask an AI assistant for — and run it side by side in Copilot and your current tool. Measure time to resolution and tokens used. The benchmark is a useful signal, but your own workflow is the only test that matters.
No comments :
Post a Comment